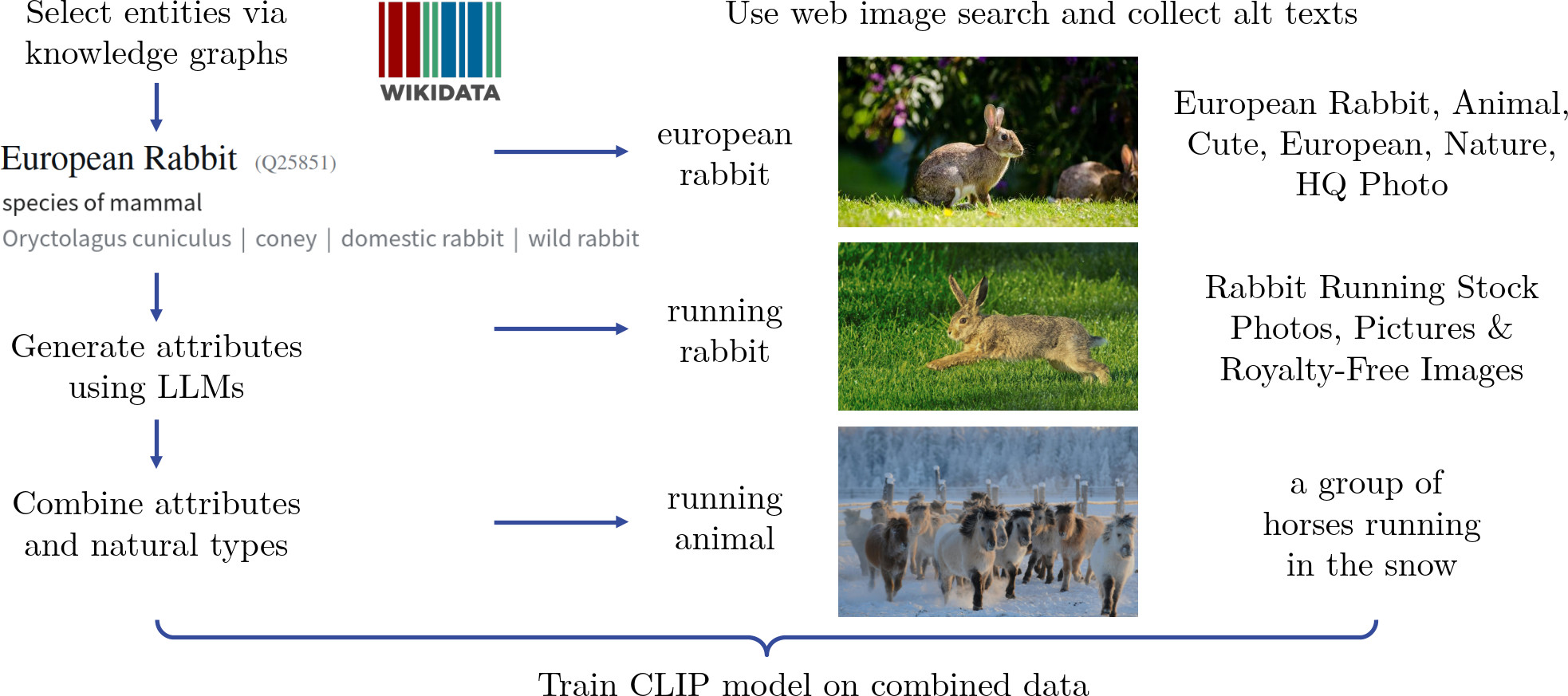
Training high-quality CLIP models typically requires enormous datasets, which limits the development of domain-specific models - especially in areas that even the largest CLIP models do not cover well - and drives up training costs. This poses challenges for scientific research that needs fine-grained control over the training procedure of CLIP models. In this work, we show that by employing smart web search strategies enhanced with knowledge graphs, a robust CLIP model can be trained from scratch with considerably less data. Specifically, we demonstrate that an expert foundation model for living organisms can be built using just 10M images. Moreover, we introduce EntityNet, a dataset comprising 33M images paired with 46M text descriptions, which enables the training of a generic CLIP model in significantly reduced time.
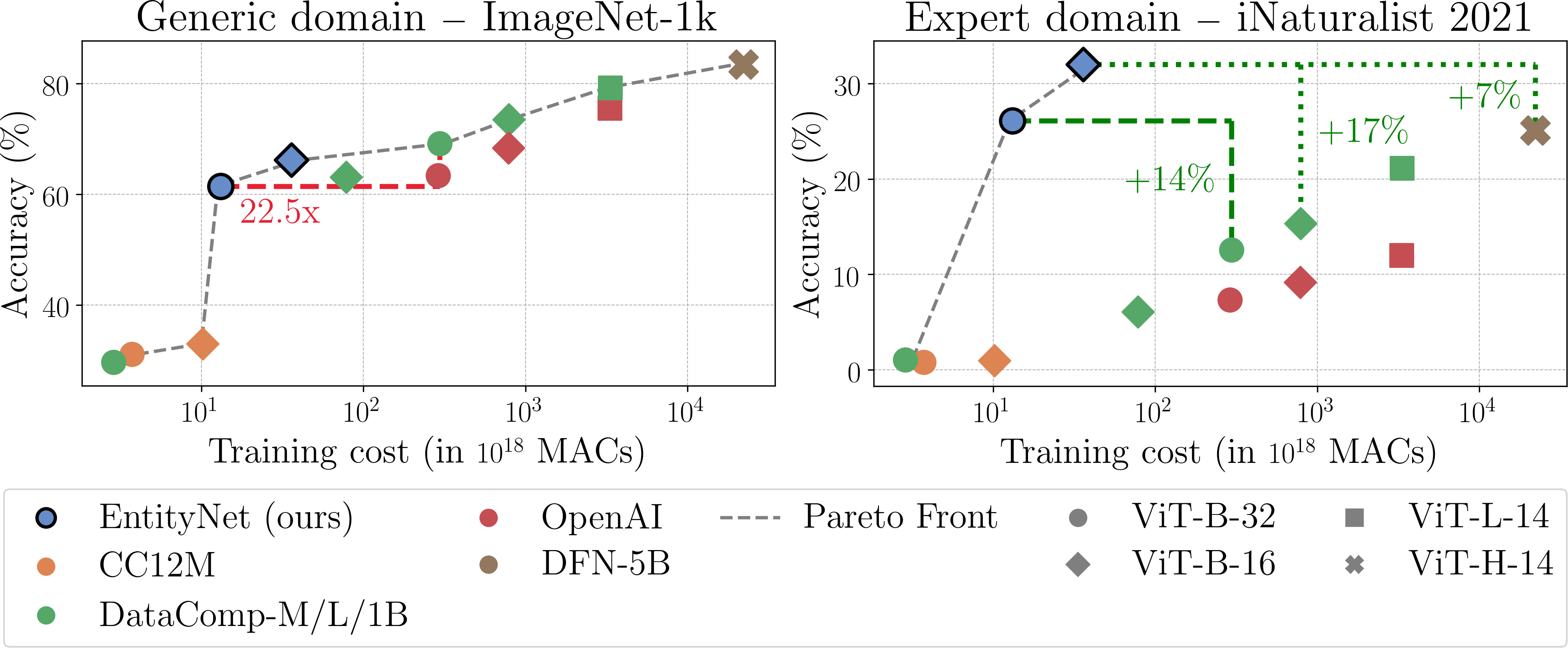
We train CLIP models on our EntityNet dataset with an improved quality-cost trade-off, for a generic (left) or an expert domain (right).

Training on a mix of knowledge graph information and alt text improves over training on only one of the two.
This work was funded by the Deutsche Forschungsgemeinschaft (DFG, German Research Foundation) – Project-ID 499552394 – SFB 1597 – Project-ID 417962828 – Project-ID 539134284. The authors acknowledge support from the state of Baden-Württemberg through bwHPC.
@inproceedings{ging2025entitynet,
author = {Simon Ging and Sebastian Walter and Jelena Bratulić and Johannes Dienert and Hannah Bast and Thomas Brox},
title = {Using Knowledge Graphs to Harvest Datasets for Efficient CLIP Model Training},
booktitle = {Pattern Recognition - 46th {DAGM} German Conference, {DAGM} {GCPR} 2025, Freiburg, Germany, September 23-26, 2025, Proceedings), 2025},
series = {Lecture Notes in Computer Science},
publisher = {Springer},
year = {2025},
note = {To appear},
}